SEO: Sitemap y robots.txt

¿Qué es y para que sirve el Sitemap?
El posicionamiento en buscadores de los sitios que diseñamos como consultores SEO o que simplemente estamos administrando tiene una enorme importancia en un entorno tan competitivo como es la web de hoy en día. De posicionamiento web depende muchas veces el éxito o fracaso del sitio y por eso tenemos que hacer todo lo posible para informar al los buscadores de la existencia de nuestros sitio.
Un sitemap es un archivo XML que contiene una lista de las páginas del sitio junto con alguna información adicional, tal como con qué frecuencia la página cambia sus contenidos, cuándo fue su última actualización y qué tan importante es respecto al resto de las páginas del mismo sitio.
Un robots.txt en un fichero de texto que todos los buscadores tienen que leer
Construcción del sitemap
La construcción del archivo XML debe seguir una serie de pautas especificadas en el protocolo de sitemaps y después tenemos que informar a los buscadores de la existencia del mismo, para eso os vamos a explicar los siguientes pasos.
- Contenidos obligatorios del sitemap
- Ejemplo de sitemap
- Etiquetas que forman el SITEMAP
- Alojamiento del sitemap
- Envío del sitemap con robots.txt
Contenidos obligatorios del sitemap
Un Sitemap se construye usando a etiquetas XML o tags incluidas en un archivo siempre con codificación UTF-8. Los valores de datos (por contraposición a las etiquetas mismas) deben utilizar códigos de escape para ciertos caracteres especiales, tal como se acostumbra en HTML, por ejemplo:
- Las comillas dobles («) deben ser reemplazadas por «
- Los signos menor (<) y mayor (>) por < y > respectivamente.
Ejemplo sencillo de Sitemap
Este es un ejemplo de sitemap:
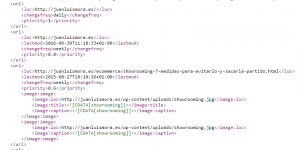
La explicación de la cabecera es bastante sencilla
- Con la primera etiqueta definimos la versión de xml en uso y la codificación en este caso UTF-8
- La segunda línea hace referencia al protocolo de uso, el 0.9
Etiquetas que forman el SITEMAP
Puedes ver toda la documentación de Google al respecto de sitemaps aquí y si prefieres un sencillo resumen te lo dejo a continuación.
- <loc>http://….</lo> url de la página Dirección url de la página que forma parte del Sitemap
- <lastmod>Fecha</lastmod>, fecha de última modificación
- Se pone en este formato: 2011-03-31
- <changefrec>Frec</changefrec>, Frecuencia de Cambio
- always, siempre, para páginas que cambian cada vez que se muestran. Típicamente, las dinámicas,
- hourly, a cada hora,
- daily, diariamente,
- weekly, semanalmente,
- monthly mensualmente,
- yearly anualmente
- never nunca, típicamente para páginas archivadas.
- <priority>Valor</priority> Prioridad Se refiere a la importancia que tiene la página que figura en respecto de las demás que componen el sitio. Es simplemente una manera de indicar prioridades relativas dentro del sitio, sin ningún efecto hacia el exterior del mismo. Valor puede tomar valores entre 0 y 1. El valor por defecto es 0.5
Alojamiento del sitemap
El archivo XML así construido se aloja en el servidor como un archivo más del sitio, con la salvedad de que puede contener las URL contenidas en el mismo directorio en que se encuentra o en otros contenidos en él. Normalmente se pone en la raíz del servidor llamándolo sitemap.xml
Envío el sitemap a los servidores
A través de Google Webmaster Tools o de Yahoo Site explorer podemos proporcionar directamente la información de nuestro sitemap a los buscadores. Pero también lo podemos hacer con el archivo robots.txt.
Más información aquí: http://www.sitemaps.org/protocol.php#submit_robots
Creación del fichero robots.txt
El archivo “robots.txt” les dice a los motores de búsqueda a qué partes de tu sitio pueden acceder y consecuentemente rastrear. Este archivo se debe llamar “robots.txt”, y tiene que estar en el directorio raíz de tu sitio.
A continuación de dejo una información básica sobre robots.txt pero si de verdad quieres aprender bien cómo funciona no dejes de leer esta entrada actualizada sobre robots.txt
Su formato habitual es:
User-Agent: *
Disallow: /estilo/plantilla.css
Disallow: /recursos/
Disallow: /capcha/
Disallow: /sesiones/
Disallow: /test/
Disallow: /img/
Disallow: /css/
Sitemap: http://impresas.es/sitemap.xml
En primer lugar con User-Agent: *, especificamos el buscador al que afectará la regla, si ponemos asterisco hacemos referencia a todos los buscadores, también se puede poner por ejemplo google para hacer referencia sólo a google.. Luego deshabilitamos el acceso a todas aquellas carpetas o ficheros que no queremos que sean accedidas y por último vamos a indicar donde está nuestro sitemap y de esta forma todos los robots que pasen por es sitio podrán localizar fácilmente nuestro sitemap.
Más sobre SEO, Sitemap y Robots.txt
El sitemap y el archivo robots.txt son dos elementos clave en el SEO (Search Engine Optimization) que juegan un papel importante en la indexación y visibilidad de un sitio web en los motores de búsqueda. A continuación, te explicaré en qué consisten y cómo se utilizan:
Sitemap:
Un sitemap, también conocido como mapa del sitio, es un archivo XML que contiene una lista de todas las páginas de un sitio web. Su objetivo principal es proporcionar a los motores de búsqueda una estructura clara y fácil de seguir de todas las páginas y contenido disponible en el sitio. El sitemap ayuda a los motores de búsqueda a descubrir e indexar el contenido de manera más eficiente, lo que puede mejorar la visibilidad y clasificación del sitio en los resultados de búsqueda.
El sitemap debe incluir las URL principales de tu sitio, así como cualquier URL secundaria relevante que desees que se indexe. También es posible incluir información adicional, como la frecuencia de actualización de las páginas y la prioridad relativa de cada URL. Una vez que hayas creado tu sitemap, puedes enviarlo a los motores de búsqueda a través de Google Search Console u otras herramientas similares.
Robots.txt:
El archivo robots.txt es un archivo de texto que se encuentra en la raíz del sitio web y proporciona instrucciones a los motores de búsqueda sobre qué páginas o secciones del sitio deben rastrear y cuáles deben ignorar. Es importante destacar que el archivo robots.txt no impide que las páginas se indexen, solo indica a los motores de búsqueda si deben o no acceder a ciertas áreas del sitio.
El archivo robots.txt utiliza directivas como «Disallow» y «Allow» para controlar el rastreo de los robots de los motores de búsqueda. Por ejemplo, si deseas bloquear el acceso a una carpeta específica del sitio, puedes agregar la siguiente línea en tu archivo robots.txt: «Disallow: /carpeta-a-bloquear/». Por otro lado, si deseas permitir el acceso a un archivo o carpeta específica, puedes utilizar la directiva «Allow».
Es importante tener en cuenta que los robots de los motores de búsqueda respetarán las instrucciones del archivo robots.txt, pero no todos los robots siguen las mismas directivas. Algunos motores de búsqueda pueden interpretar el archivo de manera ligeramente diferente, por lo que es recomendable verificar el comportamiento en cada caso.
En resumen, el sitemap ayuda a los motores de búsqueda a descubrir e indexar el contenido de tu sitio de manera eficiente, mientras que el archivo robots.txt proporciona instrucciones sobre qué partes del sitio deben ser rastreadas o ignoradas por los robots de los motores de búsqueda. Utilizar ambos de manera adecuada puede ayudar a mejorar la visibilidad y clasificación de tu sitio web en los resultados de búsqueda.

Gracias por el articulo, lo he entendido bastante bien por que lo has explicado de manera bastante sencilla y entendible, en otras paginas he visto turoriales hiperlargos que no se entendian nada :$
Hola Juan Luis,
¿crees que puedo utilizar este ejemplo de robots.txt para mi tienda en Magento?
Gracias
No para nada, ese es según la estructura de un PrestaShop
tengo problemas con mi sitio podras ayudarme? gracias
Buenas tardes, alguien sabe como se podría poner para que los buscadores no indexen todas las url que termine mi web que acaben con /r/ por ejemplo. http://www.midominio.com/articulo/134/r/
es que google me detecta duplicidades con esas url terminadas /r/
Gracias
¿Todavía se hace eso de poner el sitemap en el robots.txt? Por ahí leí que ya no es necesario, yo simplemente lo envío a Webmasters Tools y funciona.
Sólo existe Google como buscador?
estás dado de alta en todos los que existen?
Si lo pones allí cualquier buscador podrá encontrarlo y rastrear el sitio.
Hola Juan Luis.
Encantado de volver a saludarte.
El fichero robot.txt que generastes en septiembre del 2013, debemos de volver a generarlo de nuevo en Prestashops/preferencias/SEO&URLs.
Me esplico, me refiero a refrescarlo a cada cierto tiempo como hacemos con Sitemaps.
Saludos.
Juan Alberto
Pero si deshabilitamos los módulos en el robots.txt, las imágenes que tenemos en ellos no se indexan.¿Esto hasta qué punto es importante? Gracias !!!
Tienes razón, es cuestión de conocer los módulos usados y la importancia de sus imágenes
Hola Juan, gracias por tu artículo…
Tengo algunas preguntas, le agradecería su colaboración:
-Si mi web se actualiza a diario, debo hacer un sitemap a diario para herramientas de google? y este sitemap debe llevar el mismo nombre para subirlo a la raiz, o es por ejemplo seria sitemap1.xml, sitemap2,xml …. sitemap 213.xml…
– Si hago los sitemaps, con un gestor para ello, porque google no me subdivide mi web; es decir, la raiz y de alli mostrar otras más, solo veo dos…
– Si hago sitemaps, y es para que google analice todo el contenido de mi web, entonces para que hago el robots.txt??? si no lo hago en el probador de google me dice que revisa toda mi web, esto es así o es mejor hacer el robots.txt con esta info:
User-agent: *
Disallow:
Gracias por la atención prestada.
Un abrazo cordial desde Colombia.
Hola, Tengo una pagina y tengo paginacion en ella, y no quiere que se indexe en google ya que es el mismo contenido que el post, como lo quito la paginacion ya he probado pero creo no funciona, o cuanto tengo que esperar para que google rastree mi sitio nuevamente. Probe con Disallow: /page/
¿Qué has probado?
En principio si le pones noindex dejará de indexarse y luego puedes borrarlas desde WMT a la vez que cortar en robots.txt
si activas contenidos deberías actualizar sitemap.
Lo demás no es como tu lo entiendes, el sitemap es solo un mapa que Google sigue o no según le de pero no quiere decir que solo coja lo que este en el. Para bloquear accesos debes usar robots.txt
Buenas José Antonio… Verás que últimamente no respondo los comentarios lo que se dice pronto :)
ese fichero depende de la estructura, en principio si no has tocado mucho puedes seguir usando el mismo