Des-indexado Masivo de Parámetros dinámicos en Google
Al hilo de un test que acaba de hacer público @Mjcachon desde su cuenta de Twitter y para hacer pública una pregunta que desde hace años me hacen casi todos los desarrolladores sobre des-indexado de parámetros dinámicos me tomo la libertad de añadir un par de pruebas al experimento de Mjcachon sobre des-indexado o borrado de urls del índice de Google.
Prueba 1: Usar la herramienta eliminación de url de SC con urls dinámicas.
Esto es algo que he probado en otras ocasiones con resultados, si bien siempre lo he acompañado de otras técnicas complementarias. Básicamente voy a entender esta herramienta de SC como si se tratara de la interpretación que se hace de un fichero robots.txt:
Se eliminarán todas las URL incluidas en el directorio ….//dominio.xxx/directorio de los resultados de búsqueda de Google.
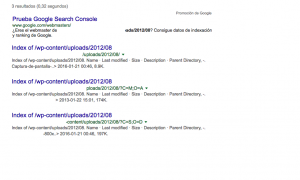
Resultado de Prueba 1
En menos de 24 horas ha pasado exactamente lo que dije. No queda nada que empiece por ?C en el site de esa carpeta.
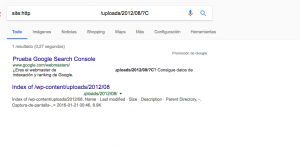
Usar Noindex en robots.txt para solicitar el des-indexado de urls dinámicas
Es simplemente usar la directiva Noindex en robots.txt para bloquear en este caso este tipo de urls también indexadas en Google:
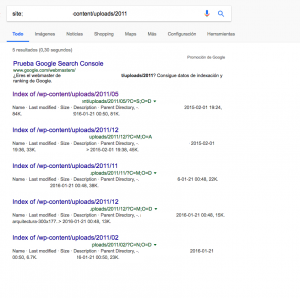
Que llevan una estructura similar a la del ejemplo anterior pero cambiando 2012 por 2011. En este caso haré una prueba algo más amplia colocando en robots.txt este código: Noindex: /wp-content/uploads/2011/*/?C. Con lo cual debería des-indexar todo lo contenido en subcarpetas de 2011 y que comiencen por ?C. Para hacer esta parte he realizado un ping desde SC a todas las urls que deberían ser des-indexadas justo antes de hacer la modificación en robots.txt porque de hacerlo al revés la herramienta de ping daba un error al entender la directiva Noindex como un Disallow.
Resultado de la Prueba 2
- Pasadas 24 horas no se ha obtenido ningún resultado.
- Pasado casi un mes sigue habiendo urls en esa carpeta con el parámetro C
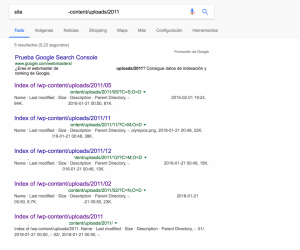
Por tanto concluyo que el noindex en robots.txt no tiene utilidad para este caso.
Prueba 3: Borrado con devolución de error 403
Esta es una prueba que hago ya que al arreglar el problema por el que se estaban indexando los índices del servidor Apache ahora la web devuelve un 403 en esos casos así que vamos a ver cuánto tarda en des-indexar y lo actualizaré en cuanto lo sepa.

Yo tengo este problema, y las urls que supuestamente tienen esto (Se ha indexado aunque un archivo robots.txt la ha bloqueado) aparece la palabra «label». Y no se como arreglarlo
Quizá esto te ayude https://masterblogging.com/custom-robots-txt/